LakeSoul General Concepts Introduction
LakeSoul is an end-to-end real-time lake warehouse storage framework that uses an open architecture design to achieve high-performance reading and writing (Upsert and Merge on Read) through the NativeIO layer, and uniformly supports multiple computing engines, including batch processing (Spark) , stream processing (Flink), MPP (Presto), AI (PyTorch, Pandas, Ray), which can be deployed in Hadoop clusters and Kubernetes clusters. The overall architecture of LakeSoul is shown in the figure below:
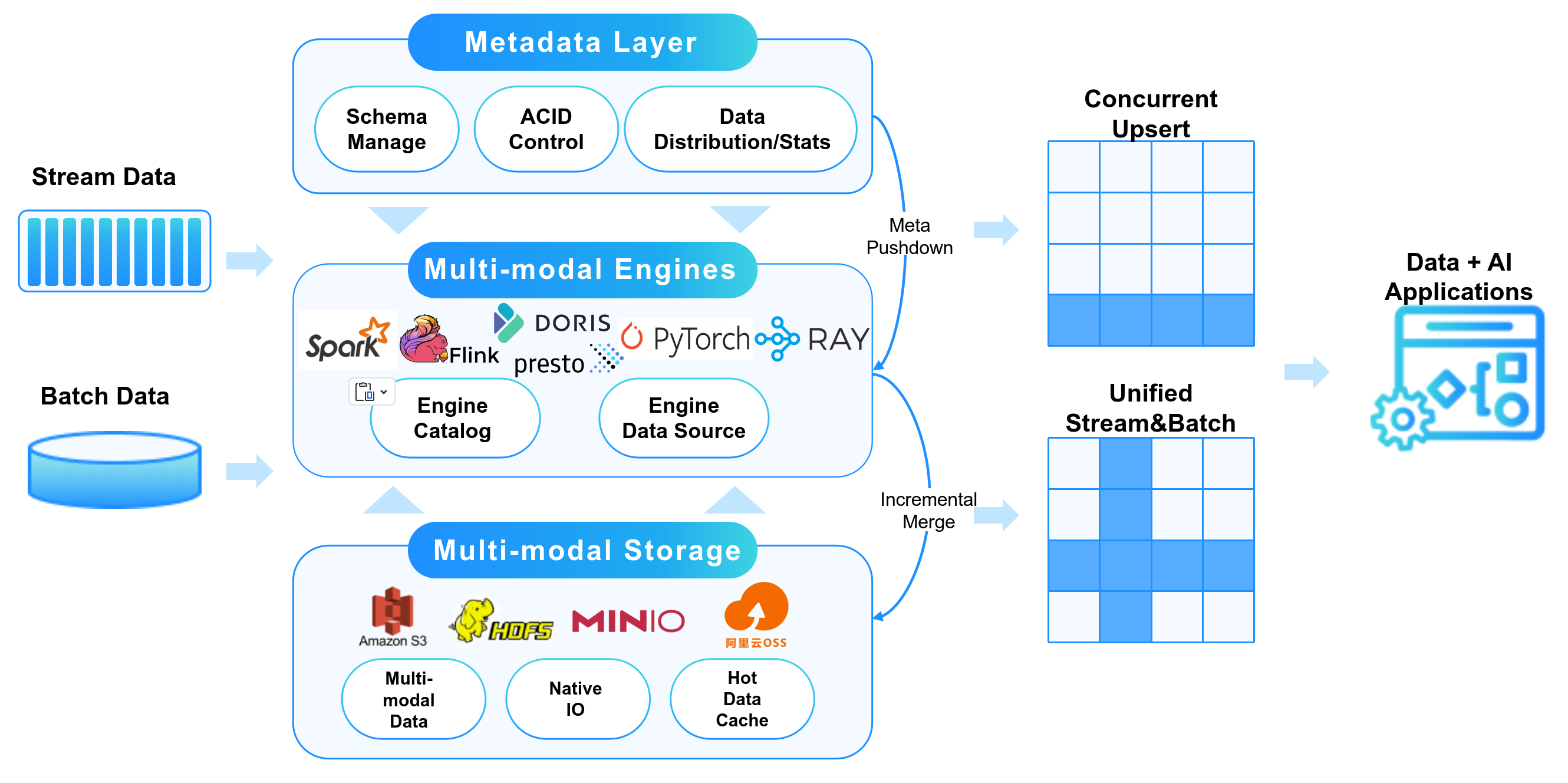
LakeSoul Architecture
-
Metadata management layer. Centralized metadata management, write concurrency atomicity and consistency control, read version isolation (MVCC), etc. are implemented through PostgreSQL. Through the powerful transaction capabilities of PostgreSQL, automatic concurrent write conflict resolution (Write conflict reconsiliation) and end-to-end strictly once (Exactly Once) guarantee are realized. Through PostgreSQL's Trigger-Notify event listening mechanism, functions such as automatic detached elastic compaction and expired data cleaning are realized, thereby achieving "autonomy" "style" management capabilities.
In addition, centralized metadata management can also easily realize unified management of multiple sets of storage in one lake warehouse instance. For example, data on multiple S3 buckets and multiple HDFS clusters can all be managed in one lake warehouse metadata. .
-
NativeIO layer. Vectorized Parquet file reading and writing implemented in Rust. For real-time update scenarios, a "single-layer" LSM-Tree-like method is used. The primary key table is fragmented according to the primary key hash, sorted and written, and automatically merged during reading, thus realizing the Upsert function. The NativeIO layer has made a lot of performance optimizations for object storage and MOR scenarios, which has greatly improved the IO performance of Hucang. The NativeIO layer also implements column clipping, Filter pushdown and other functions.
The NativeIO layer uses the native IO library implemented by Rust, and uniformly encapsulates Java and Python interfaces, allowing LakeSoul to easily implement native connectors with various big data and AI frameworks, eliminating the need for conversion overhead in file formats or memory, and improving execution efficiency.
The NativeIO layer supports common storage services such as HDFS, S3, OSS, OBS, and MinIO.
-
Engine docking layer. We are also continuously integrating Catalog and DataSource that implement frameworks such as Spark, Flink, Presto, PyTorch, Pandas, and Ray. Seamless connection between multiple engines, especially big data processing and AI computing. Therefore, LakeSoul is very suitable as the lake warehouse data base of the Data+AI integrated architecture.
Core Features of LakeSoul
LakeSoul's goal is to build an end-to-end lake warehouse platform covering data integration, real-time/batch data ETL calculations and AI calculations. The main core function points include:
- Real-time data integration. LakeSoul implements the entire database synchronization function based on Flink CDC, and currently supports MySQL, PostgreSQL, PolarDB, Oracle and other databases. For all data sources, full database synchronization, automatic new table discovery synchronization, and automatic Schema change synchronization (adding/removing columns and data type changes) are supported.
- Streaming batch calculation. LakeSoul supports frameworks such as Spark and Flink for stream and batch ETL calculations. The primary key table supports multi-stream concurrent Upsert, partial column update, and ChangeLog (CDC) reading in Flink, thereby realizing streaming incremental calculation.
- Data analysis and query. LakeSoul improves the performance of data analysis queries through a high-performance IO layer. It can also support various vectorized calculation engines. Currently, LakeSoul has implemented integration with Spark Gluten Engine to support native vectorized SQL execution on Spark. LakeSoul also integrates with high-performance vectorized query engines such as Apache Doris and Presto Velox.
- AI Computing. LakeSoul can support distributed reading of various AI and data science frameworks such as PyTorch, Ray, and Pandas for training and inference of AI models.
- Multi-tenant space and RBAC. LakeSoul has built-in multi-space isolation and permission control. Multiple workspaces can be divided into the lake warehouse, and multiple users can be added to each workspace. Metadata and physical data in different spaces achieve isolation of access permissions. Space permission isolation is effective for SQL, Java/Scala, and Python jobs, including jobs submitted to the cluster for execution.
- Autonomous management. LakeSoul provides automatically separated elastic compaction service, automatic data cleaning service, etc. to reduce the operation and maintenance workload. The detached elastic compaction service is automatically triggered by the metadata layer and executed in parallel without affecting the efficiency of writing tasks.
- Snapshots and rollbacks. LakeSoul tables can support snapshot reading and version rollback based on timestamps.
- Export to other databases. LakeSoul provides utilities to export LakeSoul table to other databases in batch or streaming mode.
Core Concepts of LakeSoul
In LakeSoul, data is organized into tables. The table supports multi-level range partitioning and supports specifying primary keys.
The partition table adopts the same directory organization structure as Hive and supports dynamic partition writing. The primary key table is stored using hash bucket sorting, and the primary key can be composed of one or more columns.
When creating a table, you can use Spark Dataframe, Spark SQL, Flink SQL, etc. When creating a table, you can directly use the partition by clause to specify the partition column, use the table attribute hashPartitions to specify the primary key column, and use the table attribute hashBucketNum to specify the number of hash shards.
All data types native to Spark and Flink can be used when creating tables. Data types are translated into Apache Arrow types and ultimately into Parquet file types. Types support multi-level nesting (Struct type).
No Primary Key Table
No primary key tables can support multi-level partitioning, but do not have primary keys. Non-primary key tables can only be appended in Append mode. Suitable for scenarios where there is no clear primary key, such as log data, etc. Append writes to non-primary key tables can be executed concurrently, that is, multiple batch and streaming jobs can write concurrently to the table/partition.
In Spark and Flink, you can use the DataFrame and DataStream API to write, and you can use the SQL insert into statement to write to non-primary key tables. Non-primary key tables can support streaming reading in Spark and Flink. Support batch reading in Presto and AI framework.
Primary key table
A primary key table can specify multiple levels of partitioning, as well as one or more primary key columns. Primary key columns cannot be null. For the same primary key, the latest value will be automatically merged when reading.
The primary key table can only support Upsert mode for updating. Updates can be made using the Spark API or the MERGE INTO SQL statement. INSERT INTO SQL in Flink will automatically be executed in the Upsert mode.
The primary key table can support concurrent write updates and partial column updates (Partial Update). During concurrent updates, the application layer needs to ensure that the writing order does not conflict. Generally speaking, if there are multiple streams updating different columns of the primary key table at the same time, you can use concurrent updates to write, so that data conflicts will not occur and the degree of concurrency will be improved.
The primary key table can also support CDC format. For tables synchronized from the database, CDC format needs to be enabled. At the same time, the CDC format will automatically support ChangeLog semantics during Flink stream reading, thus enabling streaming incremental calculations in Flink.
Primary key tables (including CDC format tables) batch read is also supported in Apache Doris, Presto and Python.
Snapshot read
LakeSoul supports snapshot reading (Time Travel) and version rollback in Spark and Flink. Reference documents: Spark snapshot function, Flink snapshot reading.